

{kind=link}
In machine studying, bigger networks with growing parameters are being educated. Nonetheless, coaching such networks has turn into prohibitively costly. Regardless of the success of this strategy, there must be a higher understanding of why overparameterized fashions are essential. The prices related to coaching these fashions proceed to rise exponentially.
A crew of researchers from the College of Massachusetts Lowell, Eleuther AI, and Amazon developed a way often known as ReLoRA, which makes use of low-rank updates to coach high-rank networks. ReLoRA accomplishes a high-rank replace, delivering a efficiency akin to traditional neural community coaching.
Scaling legal guidelines have been recognized, demonstrating a powerful power-law dependence between community dimension and efficiency throughout completely different modalities, supporting overparameterization and resource-intensive neural networks. The Lottery Ticket Speculation means that overparameterization could be minimized, offering another perspective. Low-rank fine-tuning strategies, reminiscent of LoRA and Compacter, have been developed to deal with the restrictions of low-rank matrix factorization approaches.
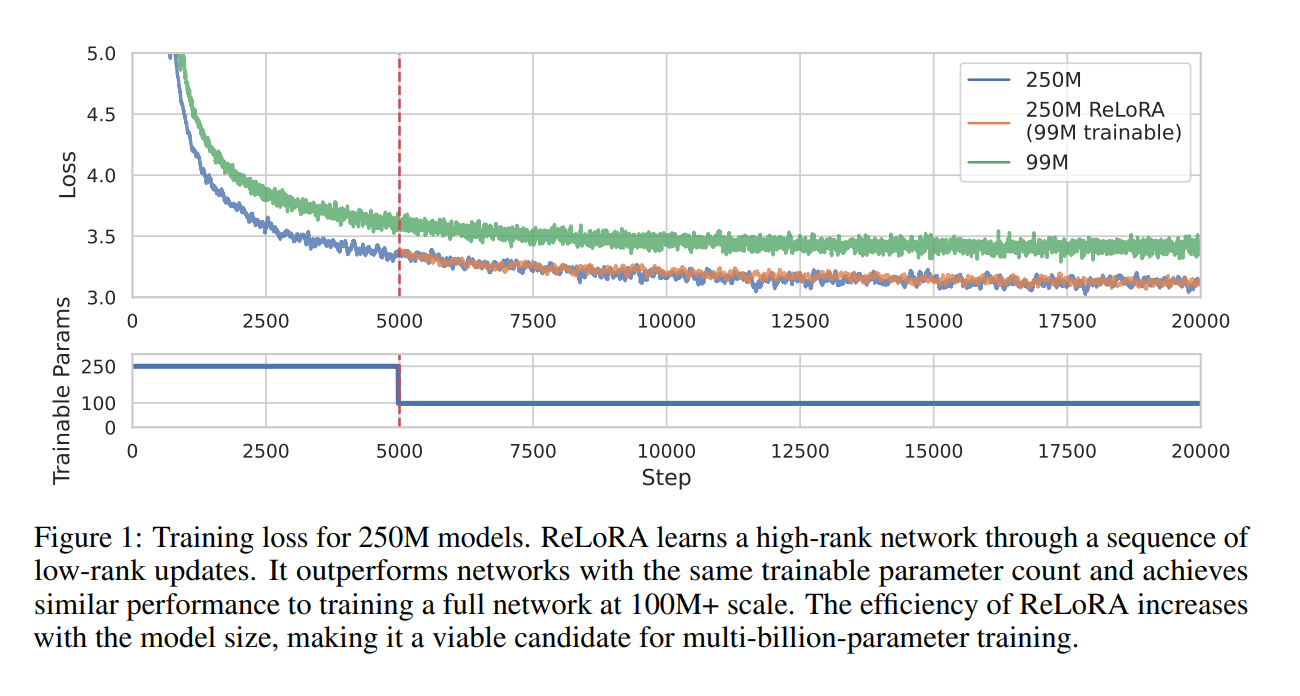
ReLoRA is utilized to coaching transformer language fashions with as much as 1.3B parameters and demonstrates comparable efficiency to common neural community coaching. The ReLoRA methodology leverages the rank of the sum property to coach a high-rank community via a number of low-rank updates. ReLoRA employs a full-rank coaching heat begin earlier than transitioning to ReLoRA and periodically merges its parameters into the principle parameters of the community, performs optimizer reset, and studying price re-warm up. The Adam optimizer and a jagged cosine scheduler are additionally utilized in ReLoRA.
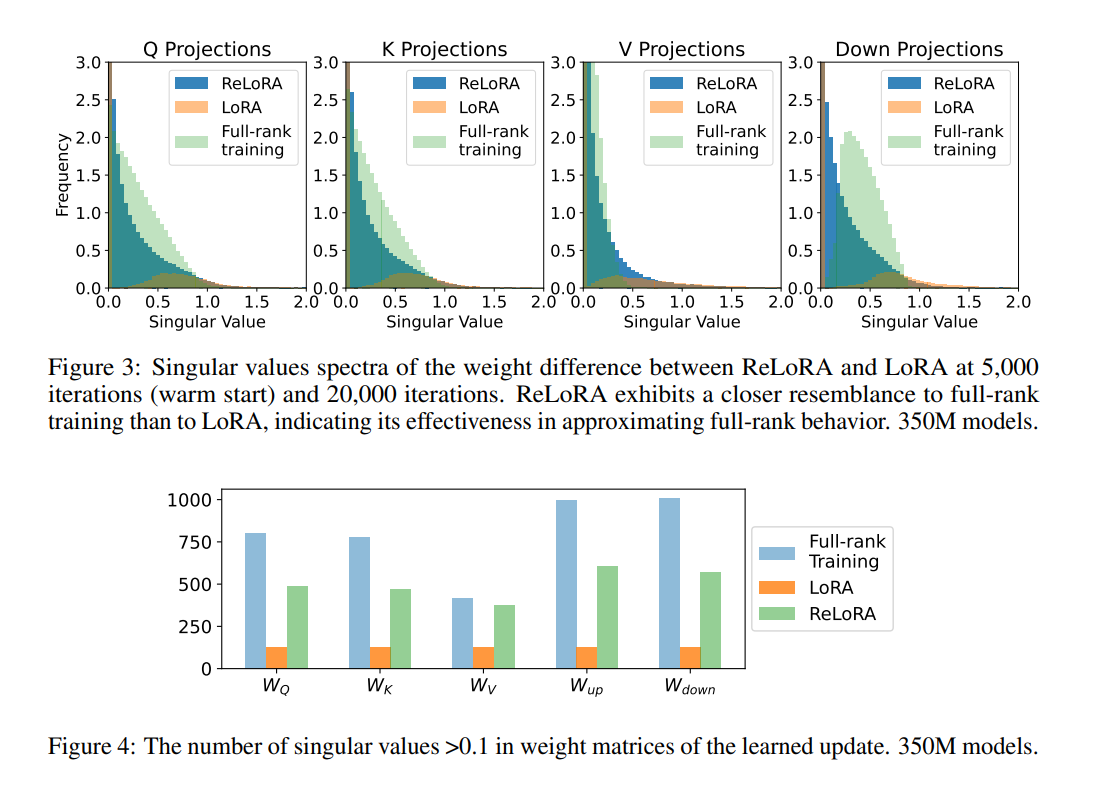
ReLoRA performs similar to common neural community coaching in upstream and downstream duties. The tactic saves as much as 5.5Gb of RAM per GPU and improves coaching pace by 9-40%, relying on the mannequin dimension and {hardware} setup. Qualitative evaluation of the singular worth spectrum exhibits that ReLoRA displays a better distribution mass between 0.1 and 1.0, paying homage to full-rank coaching, whereas LoRA has principally zero distinct values.
In conclusion, the research could be summarized in under factors:
- ReLoRA accomplishes a high-rank replace by performing a number of low-rank updates.
- It has a smaller variety of near-zero singular values in comparison with LoRA.
- ReLoRA is a parameter-efficient coaching approach that makes use of low-rank updates to coach giant neural networks with as much as 1.3B parameters.
- It saves important GPU reminiscence as much as 5.5Gb per GPU and improves coaching pace by 9-40%, relying on the mannequin dimension and {hardware} setup.
- ReLoRA outperforms the low-rank matrix factorization strategy in coaching high-performing transformer fashions.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to affix our 34k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and E mail E-newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
If you happen to like our work, you’ll love our e-newsletter..
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is obsessed with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.