
{kind=link}

Picture by Creator
Okay-Means clustering is likely one of the mostly used unsupervised studying algorithms in information science. It’s used to robotically section datasets into clusters or teams primarily based on similarities between information factors.
On this quick tutorial, we are going to learn the way the Okay-Means clustering algorithm works and apply it to actual information utilizing scikit-learn. Moreover, we are going to visualize the outcomes to know the information distribution.
Okay-Means clustering is an unsupervised machine studying algorithm that’s used to resolve clustering issues. The objective of this algorithm is to seek out teams or clusters within the information, with the variety of clusters represented by the variable Okay.
The Okay-Means algorithm works as follows:
- Specify the variety of clusters Okay that you really want the information to be grouped into.
- Randomly initialize Okay cluster facilities or centroids. This may be completed by randomly choosing Okay information factors to be the preliminary centroids.
- Assign every information level to the closest cluster centroid primarily based on Euclidean distance. The info factors closest to a given centroid are thought-about a part of that cluster.
- Recompute the cluster centroids by taking the imply of all information factors assigned to that cluster.
- Repeat steps 3 and 4 till the centroids cease shifting or the iterations attain a specified restrict. That is completed when the algorithm has converged.
Gif by Alan Jeffares
The target of Okay-Means is to attenuate the sum of squared distances between information factors and their assigned cluster centroid. That is achieved by iteratively reassigning information factors to the closest centroid and shifting the centroids to the middle of their assigned factors, leading to extra compact and separated clusters.
In these examples, we are going to use Mall Buyer Segmentation information from Kaggle and apply the Okay-Means algorithm. We may even discover the optimum variety of Okay (clusters) utilizing the Elbow technique and visualize the clusters.
Knowledge Loading
We’ll load a CSV file utilizing pandas and make “CustomerID” as an index.
import pandas as pd
df_mall = pd.read_csv("Mall_Customers.csv",index_col="CustomerID")
df_mall.head(3)
The info set has 4 columns and we’re thinking about solely three: Age, Annual Revenue, and Spending Rating of the purchasers.
Visualization
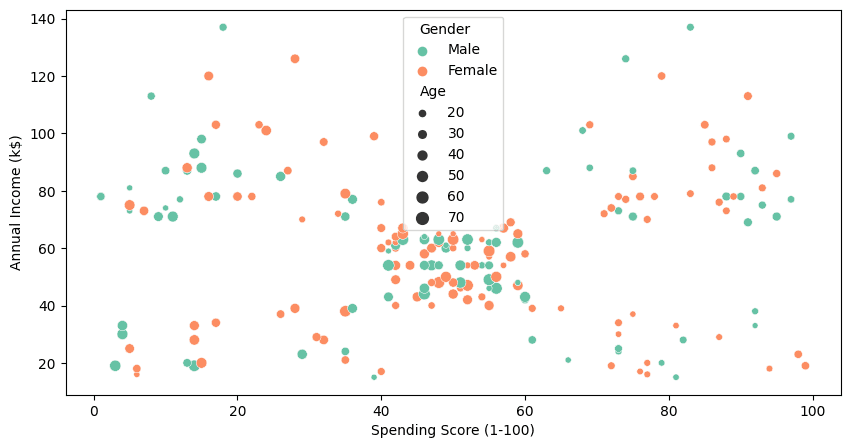
To visualise all 4 columns, we are going to use seaborn’s `scatterplot` .
import matplotlib.pyplot as plt
import seaborn as sns
plt.determine(1 , figsize = (10 , 5) )
sns.scatterplot(
information=df_mall,
x="Spending Rating (1-100)",
y="Annual Revenue (ok$)",
hue="Gender",
measurement="Age",
palette="Set2"
);
Even with out Okay-Means clustering, we will clearly see the cluster in between 40-60 spending rating and 40k to 70k annual revenue. To seek out extra clusters, we are going to use the clustering algorithm within the subsequent half.
Normalizing
Earlier than making use of a clustering algorithm, it is essential to normalize the information to get rid of any outliers or anomalies. We’re dropping the “Gender” and “Age” columns and will probably be utilizing the remainder of them to seek out the clusters.
from sklearn import preprocessing
X = df_mall.drop(["Gender","Age"],axis=1)
X_norm = preprocessing.normalize(X)
Elbow Technique
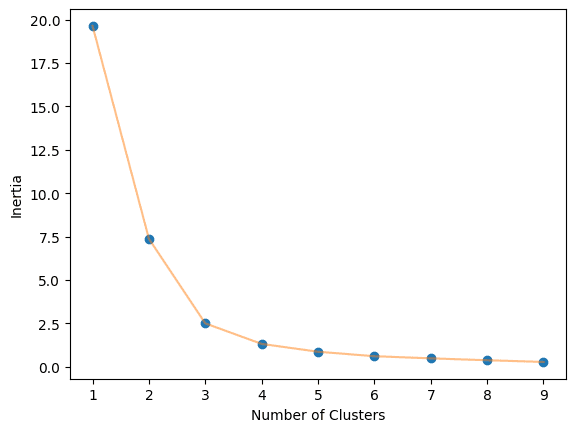
The optimum worth of Okay within the Okay-Means algorithm might be discovered utilizing the Elbow technique. This includes discovering the inertia worth of each Okay variety of clusters from 1-10 and visualizing it.
import numpy as np
from sklearn.cluster import KMeans
def elbow_plot(information,clusters):
inertia = []
for n in vary(1, clusters):
algorithm = KMeans(
n_clusters=n,
init="k-means++",
random_state=125,
)
algorithm.match(information)
inertia.append(algorithm.inertia_)
# Plot
plt.plot(np.arange(1 , clusters) , inertia , 'o')
plt.plot(np.arange(1 , clusters) , inertia , '-' , alpha = 0.5)
plt.xlabel('Variety of Clusters') , plt.ylabel('Inertia')
plt.present();
elbow_plot(X_norm,10)
We obtained an optimum worth of three.
KMeans Clustering
We’ll now use KMeans algorithm from scikit-learn and supply it the Okay worth. After that we are going to match it on our coaching dataset and get cluster labels.
algorithm = KMeans(n_clusters=3, init="k-means++", random_state=125)
algorithm.match(X_norm)
labels = algorithm.labels_
We are able to use scatterplot to visualise the three clusters.
sns.scatterplot(information = X, x = 'Spending Rating (1-100)', y = 'Annual Revenue (ok$)', hue = labels, palette="Set2");
- “0”: From excessive spender with low annual revenue.
- “1”: Common to excessive spender with medium to excessive annual revenue.
- “2”: From Low spender with Excessive annual revenue.
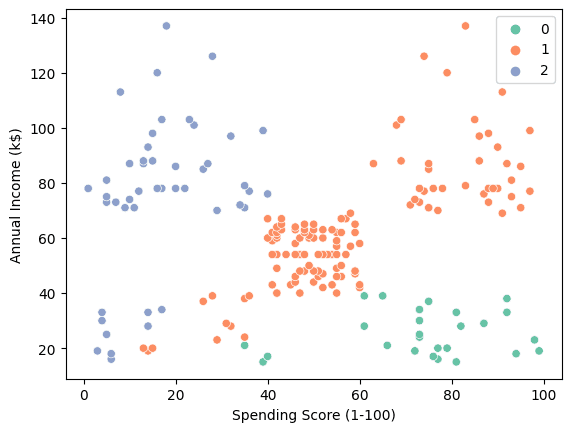
This perception can be utilized to create customized adverts, growing buyer loyalty and boosting income.
Utilizing totally different options
Now, we are going to use Age and Spending Rating because the function for the clustering algorithm. It can give us an entire image of buyer distribution. We’ll repeat the method of normalizing the information.
X = df_mall.drop(["Gender","Annual Income (k$)"],axis=1)
X_norm = preprocessing.normalize(X)
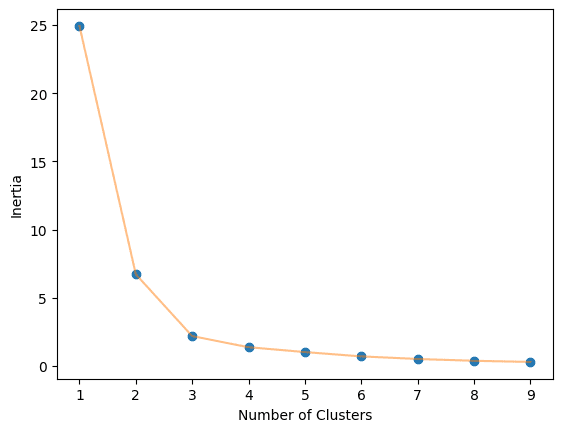
Calculate the optimum variety of clusters.
Practice the Okay-Means algorithm on Okay=3 clusters.
algorithm = KMeans(n_clusters=3, init="k-means++", random_state=125)
algorithm.match(X_norm)
labels = algorithm.labels_
Use a scatter plot to visualise the three clusters.
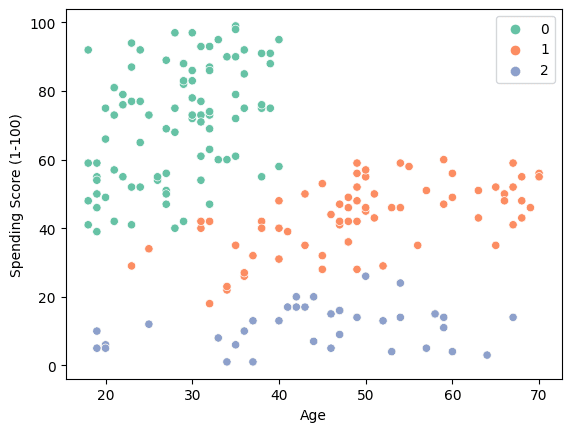
sns.scatterplot(information = X, x = 'Age', y = 'Spending Rating (1-100)', hue = labels, palette="Set2");
- “0”: Younger Excessive spender.
- “1”: Medium spender from center age to previous ages.
- “2”: Low spenders.
The consequence means that firms can enhance income by concentrating on people aged 20-40 with disposable revenue.
We are able to even go deep by visualizing the boxplot of spending scores. It clearly exhibits that the clusters are fashioned primarily based on spending habits.
sns.boxplot(x = labels, y = X['Spending Score (1-100)']);
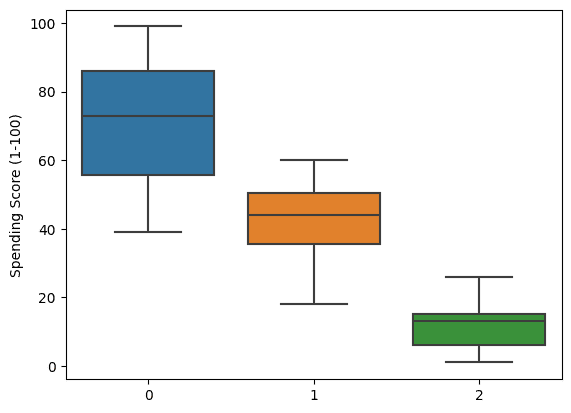
On this Okay-Means clustering tutorial, we explored how the Okay-Means algorithm might be utilized for buyer segmentation to allow focused promoting. Although Okay-Means will not be an ideal, catch-all clustering algorithm, it supplies a easy and efficient method for a lot of real-world use circumstances.
By strolling by the Okay-Means workflow and implementing it in Python, we gained perception into how the algorithm capabilities to partition information into distinct clusters. We discovered strategies like discovering the optimum variety of clusters with the elbow technique and visualizing the clustered information.
Whereas scikit-learn supplies many different clustering algorithms, Okay-Means stands out for its velocity, scalability, and ease of interpretation.
Abid Ali Awan (@1abidaliawan) is a licensed information scientist skilled who loves constructing machine studying fashions. At present, he’s specializing in content material creation and writing technical blogs on machine studying and information science applied sciences. Abid holds a Grasp’s diploma in Expertise Administration and a bachelor’s diploma in Telecommunication Engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college kids combating psychological sickness.