
{kind=link}

Picture by Creator
Because the wave of curiosity in Giant Language Fashions (LLMs) surges, many builders and organisations are busy constructing purposes harnessing their energy. Nevertheless, when the pre-trained LLMs out of the field don’t carry out as anticipated or hoped, the query on the way to enhance the efficiency of the LLM software. And ultimately we get to the purpose of the place we ask ourselves: Ought to we use Retrieval-Augmented Technology (RAG) or mannequin finetuning to enhance the outcomes?
Earlier than diving deeper, let’s demystify these two strategies:
RAG: This strategy integrates the ability of retrieval (or looking) into LLM textual content era. It combines a retriever system, which fetches related doc snippets from a big corpus, and an LLM, which produces solutions utilizing the knowledge from these snippets. In essence, RAG helps the mannequin to “lookup” exterior info to enhance its responses.
Picture by Creator
Finetuning: That is the method of taking a pre-trained LLM and additional coaching it on a smaller, particular dataset to adapt it for a selected job or to enhance its efficiency. By finetuning, we’re adjusting the mannequin’s weights primarily based on our knowledge, making it extra tailor-made to our software’s distinctive wants.
Picture by Creator
Each RAG and finetuning function highly effective instruments in enhancing the efficiency of LLM-based purposes, however they handle totally different elements of the optimisation course of, and that is essential relating to selecting one over the opposite.
Beforehand, I’d usually counsel to organisations that they experiment with RAG earlier than diving into finetuning. This was primarily based on my notion that each approaches achieved comparable outcomes however different by way of complexity, value, and high quality. I even used as an example this level with diagrams akin to this one:
Picture by Creator
On this diagram, varied elements like complexity, value, and high quality are represented alongside a single dimension. The takeaway? RAG is less complicated and cheaper, however its high quality may not match up. My recommendation normally was: begin with RAG, gauge its efficiency, and if discovered missing, shift to finetuning.
Nevertheless, my perspective has since advanced. I consider it’s an oversimplification to view RAG and finetuning as two methods that obtain the identical end result, simply the place one is simply cheaper and fewer complicated than the opposite. They’re essentially distinct — as a substitute of co-linear they’re really orthogonal — and serve totally different necessities of an LLM software.
To make this clearer, take into account a easy real-world analogy: When posed with the query, “Ought to I exploit a knife or a spoon to eat my meal?”, essentially the most logical counter-question is: “Properly, what are you consuming?” I requested family and friends this query and everybody instinctively replied with that counter-question, indicating that they don’t view the knife and spoon as interchangeable, or one as an inferior variant of the opposite.
On this weblog put up, we’ll dive deep into the nuances that differentiate RAG and finetuning throughout varied dimensions which might be, for my part, essential in figuring out the optimum approach for a particular job. Furthermore, we’ll be taking a look at among the hottest use instances for LLM purposes and use the size established within the first half to establish which approach is likely to be finest fitted to which use case. Within the final a part of this weblog put up we’ll establish extra elements that needs to be thought of when constructing LLM purposes. Every a kind of may warrant its personal weblog put up and subsequently we will solely contact briefly on them within the scope of this put up.
Choosing the proper approach for adapting massive language fashions can have a serious influence on the success of your NLP purposes. Deciding on the incorrect strategy can result in:
- Poor mannequin efficiency in your particular job, leading to inaccurate outputs.
- Elevated compute prices for mannequin coaching and inference if the approach isn’t optimized on your use case.
- Extra improvement and iteration time if you should pivot to a unique approach afterward.
- Delays in deploying your software and getting it in entrance of customers.
- A scarcity of mannequin interpretability if you happen to select a very complicated adaptation strategy.
- Problem deploying the mannequin to manufacturing as a consequence of measurement or computational constraints.
The nuances between RAG and finetuning span mannequin structure, knowledge necessities, computational complexity, and extra. Overlooking these particulars can derail your mission timeline and price range.
This weblog put up goals to stop wasted effort by clearly laying out when every approach is advantageous. With these insights, you’ll be able to hit the bottom working with the precise adaptation strategy from day one. The detailed comparability will equip you to make the optimum expertise alternative to realize your small business and AI objectives. This information to choosing the precise instrument for the job will set your mission up for fulfillment.
So let’s dive in!
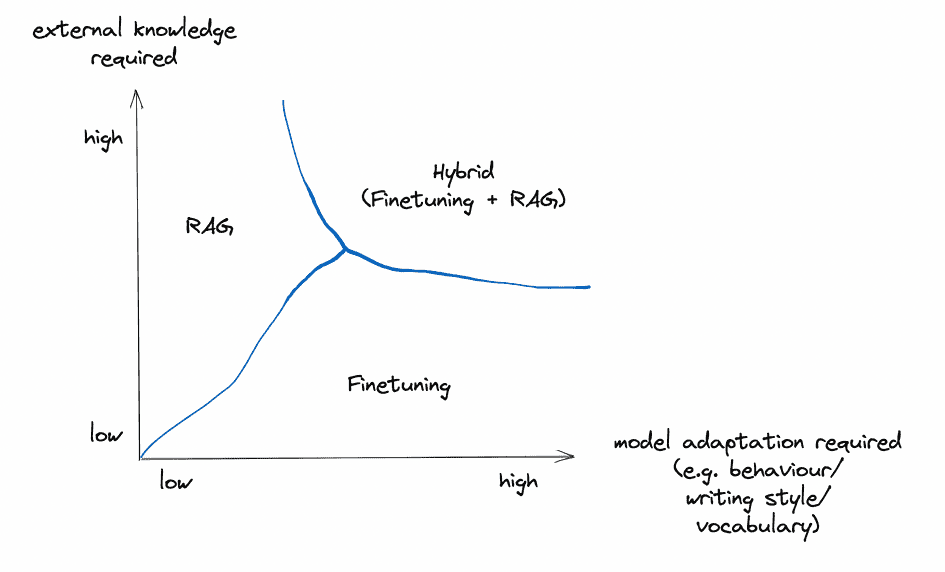
Earlier than we select RAG vs Fintuning, we should always assess the necessities of our LLM mission alongside some dimensions and ask ourselves a couple of questions.
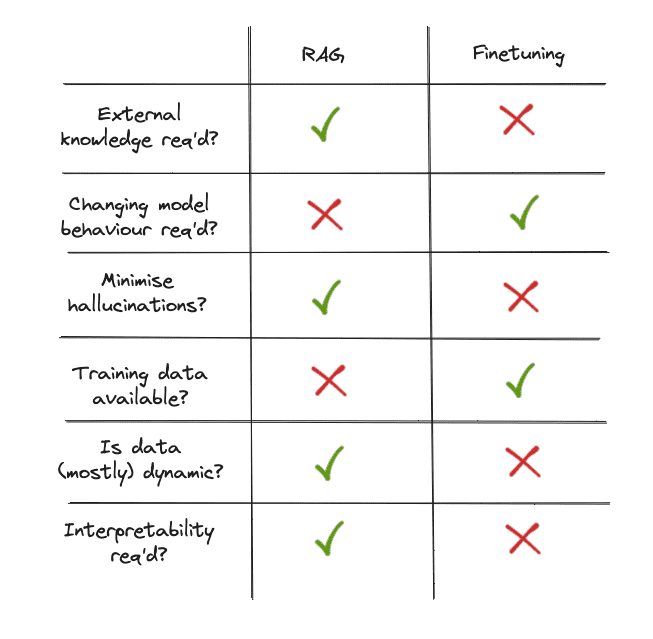
Does our use case require entry to exterior knowledge sources?
When selecting between finetuning an LLM or utilizing RAG, one key consideration is whether or not the appliance requires entry to exterior knowledge sources. If the reply is sure, RAG is probably going the higher possibility.
RAG methods are, by definition, designed to reinforce an LLM’s capabilities by retrieving related info from data sources earlier than producing a response. This makes this method well-suited for purposes that want to question databases, paperwork, or different structured/unstructured knowledge repositories. The retriever and generator parts will be optimised to leverage these exterior sources.
In distinction, whereas it’s potential to finetune an LLM to be taught some exterior data, doing so requires a big labelled dataset of question-answer pairs from the goal area. This dataset have to be up to date because the underlying knowledge modifications, making it impractical for regularly altering knowledge sources. The finetuning course of additionally doesn’t explicitly mannequin the retrieval and reasoning steps concerned in querying exterior data.
So in abstract, if our software must leverage exterior knowledge sources, utilizing a RAG system will seemingly be more practical and scalable than making an attempt to “bake in” the required data by finetuning alone.
Do we have to modify the mannequin’s behaviour, writing type, or domain-specific data?
One other essential facet to contemplate is how a lot we’d like the mannequin to regulate its behaviour, its writing type, or tailor its responses for domain-specific purposes.
Finetuning excels in its potential to adapt an LLM’s behaviour to particular nuances, tones, or terminologies. If we wish the mannequin to sound extra like a medical skilled, write in a poetic type, or use the jargon of a particular business, finetuning on domain-specific knowledge permits us to realize these customisations. This potential to affect the mannequin’s behaviour is important for purposes the place alignment with a selected type or area experience is important.
RAG, whereas highly effective in incorporating exterior data, primarily focuses on info retrieval and doesn’t inherently adapt its linguistic type or domain-specificity primarily based on the retrieved info. It should pull related content material from the exterior knowledge sources however may not exhibit the tailor-made nuances or area experience {that a} finetuned mannequin can supply.
So, if our software calls for specialised writing kinds or deep alignment with domain-specific vernacular and conventions, finetuning presents a extra direct path to attaining that alignment. It gives the depth and customisation essential to genuinely resonate with a particular viewers or experience space, guaranteeing the generated content material feels genuine and well-informed.
Fast recap
These two elements are by far a very powerful ones to contemplate when deciding which technique to make use of to spice up LLM software efficiency. Curiously, they’re, for my part, orthogonal and can be utilized independently (and likewise be mixed).
Picture by Creator
Nevertheless, earlier than diving into the use instances, there are a couple of extra key elements we should always take into account earlier than selecting a technique:
How essential is it to suppress hallucinations?
One draw back of LLMs is their tendency to hallucinate — making up information or particulars that haven’t any foundation in actuality. This may be extremely problematic in purposes the place accuracy and truthfulness are essential.
Finetuning might help cut back hallucinations to some extent by grounding the mannequin in a particular area’s coaching knowledge. Nevertheless, the mannequin should fabricate responses when confronted with unfamiliar inputs. Retraining on new knowledge is required to constantly minimise false fabrications.
In distinction, RAG methods are inherently much less liable to hallucination as a result of they floor every response in retrieved proof. The retriever identifies related information from the exterior data supply earlier than the generator constructs the reply. This retrieval step acts as a fact-checking mechanism, lowering the mannequin’s potential to confabulate. The generator is constrained to synthesise a response supported by the retrieved context.
So in purposes the place suppressing falsehoods and imaginative fabrications is important, RAG methods present in-built mechanisms to minimise hallucinations. The retrieval of supporting proof previous to response era offers RAG a bonus in guaranteeing factually correct and truthful outputs.
How a lot labelled coaching knowledge is out there?
When deciding between RAG and finetuning, an important issue to contemplate is the quantity of domain- or task-specific, labelled coaching knowledge at our disposal.
Finetuning an LLM to adapt to particular duties or domains is closely depending on the standard and amount of the labelled knowledge accessible. A wealthy dataset might help the mannequin deeply perceive the nuances, intricacies, and distinctive patterns of a selected area, permitting it to generate extra correct and contextually related responses. Nevertheless, if we’re working with a restricted dataset, the enhancements from finetuning is likely to be marginal. In some instances, a scant dataset may even result in overfitting, the place the mannequin performs nicely on the coaching knowledge however struggles with unseen or real-world inputs.
Quite the opposite, RAG methods are unbiased from coaching knowledge as a result of they leverage exterior data sources to retrieve related info. Even when we don’t have an in depth labelled dataset, a RAG system can nonetheless carry out competently by accessing and incorporating insights from its exterior knowledge sources. The mixture of retrieval and era ensures that the system stays knowledgeable, even when domain-specific coaching knowledge is sparse.
In essence, if now we have a wealth of labelled knowledge that captures the area’s intricacies, finetuning can supply a extra tailor-made and refined mannequin behaviour. However in situations the place such knowledge is restricted, a RAG system supplies a sturdy various, guaranteeing the appliance stays data-informed and contextually conscious by its retrieval capabilities.
How static/dynamic is the information?
One other basic facet to contemplate when selecting between RAG and finetuning is the dynamic nature of our knowledge. How regularly is the information up to date, and the way crucial is it for the mannequin to remain present?
Finetuning an LLM on a particular dataset means the mannequin’s data turns into a static snapshot of that knowledge on the time of coaching. If the information undergoes frequent updates, modifications, or expansions, this could rapidly render the mannequin outdated. To maintain the LLM present in such dynamic environments, we’d need to retrain it regularly, a course of that may be each time-consuming and resource-intensive. Moreover, every iteration requires cautious monitoring to make sure that the up to date mannequin nonetheless performs nicely throughout totally different situations and hasn’t developed new biases or gaps in understanding.
In distinction, RAG methods inherently possess a bonus in environments with dynamic knowledge. Their retrieval mechanism continuously queries exterior sources, guaranteeing that the knowledge they pull in for producing responses is up-to-date. Because the exterior data bases or databases replace, the RAG system seamlessly integrates these modifications, sustaining its relevance with out the necessity for frequent mannequin retraining.
In abstract, if we’re grappling with a quickly evolving knowledge panorama, RAG gives an agility that’s onerous to match with conventional finetuning. By all the time staying linked to the latest knowledge, RAG ensures that the responses generated are in tune with the present state of data, making it a really perfect alternative for dynamic knowledge situations.
How clear/interpretable does our LLM app should be?
The final facet to contemplate is the diploma to which we’d like insights into the mannequin’s decision-making course of.
Finetuning an LLM, whereas extremely highly effective, operates like a black field, making the reasoning behind its responses extra opaque. Because the mannequin internalises the knowledge from the dataset, it turns into difficult to discern the precise supply or reasoning behind every response. This will make it tough for builders or customers to belief the mannequin’s outputs, particularly in essential purposes the place understanding the “why” behind a solution is important.
RAG methods, then again, supply a degree of transparency that’s not sometimes present in solely finetuned fashions. Given the two-step nature of RAG — retrieval after which era — customers can peek into the method. The retrieval element permits for the inspection of which exterior paperwork or knowledge factors are chosen as related. This supplies a tangible path of proof or reference that may be evaluated to know the inspiration upon which a response is constructed. The power to hint again a mannequin’s reply to particular knowledge sources will be invaluable in purposes that demand a excessive diploma of accountability or when there’s a have to validate the accuracy of the generated content material.
In essence, if transparency and the flexibility to interpret the underpinnings of a mannequin’s responses are priorities, RAG gives a transparent benefit. By breaking down the response era into distinct levels and permitting perception into its knowledge retrieval, RAG fosters higher belief and understanding in its outputs.
Abstract
Selecting between RAG and finetuning turns into extra intuitive when contemplating these dimensions. If we’d like lean in direction of accessing exterior data and valuing transparency, RAG is our go-to. Then again, if we’re working with steady labelled knowledge and intention to adapt the mannequin extra intently to particular wants, finetuning is the higher alternative.
Picture by Creator
Within the following part, we’ll see how we will assess widespread LLM use instances primarily based on these standards.
Let’s have a look at some widespread use instances and the way the above framework can be utilized to decide on the precise technique:
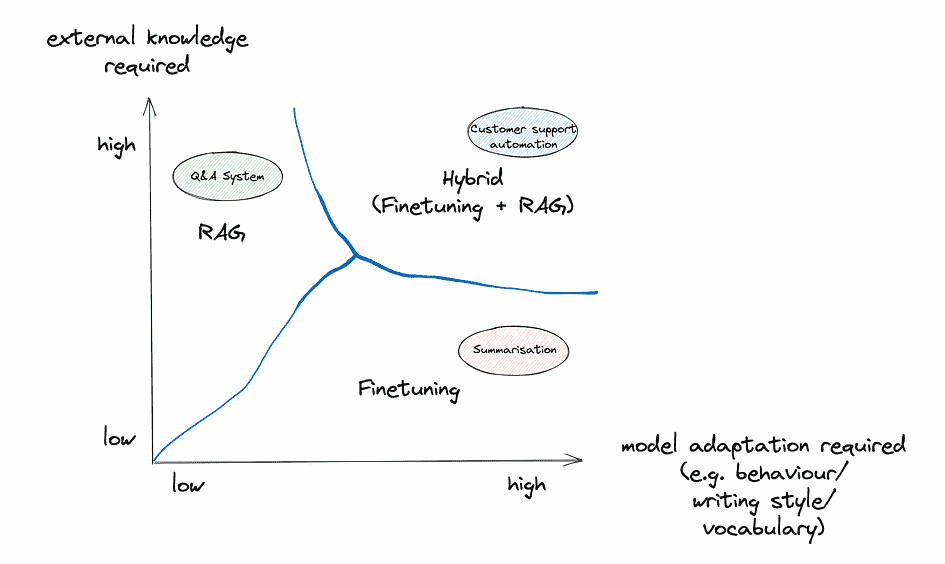
Summarisation (in a specialised area and/or a particular type)
1. Exterior data required? For the duty of summarizing within the type of earlier summaries, the first knowledge supply can be the earlier summaries themselves. If these summaries are contained inside a static dataset, there’s no need for steady exterior knowledge retrieval. Nevertheless, if there’s a dynamic database of summaries that regularly updates and the purpose is to repeatedly align the type with the latest entries, RAG is likely to be helpful right here.
2. Mannequin adaptation required? The core of this use case revolves round adapting to a specialised area or a and/or a particular writing type. Finetuning is especially adept at capturing stylistic nuances, tonal variations, and particular area vocabularies, making it an optimum alternative for this dimension.
3. Essential to minimise hallucinations? Hallucinations are problematic in most LLM purposes, together with summarisation. Nevertheless, on this use case, the textual content to be summarised is usually supplied as context. This makes hallucinations much less of a priority in comparison with different use instances. The supply textual content constrains the mannequin, lowering imaginative fabrications. So whereas factual accuracy is all the time fascinating, suppressing hallucinations is a decrease precedence for summarisation given the contextual grounding.
4. Coaching knowledge accessible? If there’s a considerable assortment of earlier summaries which might be labelled or structured in a approach that the mannequin can be taught from them, finetuning turns into a really enticing possibility. Then again, if the dataset is restricted, and we’re leaning on exterior databases for stylistic alignment, RAG may play a job, though its major energy isn’t type adaptation.
5. How dynamic is the information? If the database of earlier summaries is static or updates occasionally, the finetuned mannequin’s data will seemingly stay related for an extended time. Nevertheless, if the summaries replace regularly and there’s a necessity for the mannequin to align with the latest stylistic modifications constantly, RAG may need an edge as a consequence of its dynamic knowledge retrieval capabilities.
6. Transparency/Interpretability required? The first purpose right here is stylistic alignment, so the “why” behind a selected summarisation type is likely to be much less essential than in different use instances. That stated, if there’s a have to hint again and perceive which earlier summaries influenced a selected output, RAG gives a bit extra transparency. Nonetheless, this is likely to be a secondary concern for this use case.
Advice: For this use case finetuning seems to be the extra becoming alternative. The first goal is stylistic alignment, a dimension the place finetuning shines. Assuming there’s an honest quantity of earlier summaries accessible for coaching, finetuning an LLM would enable for deep adaptation to the specified type, capturing the nuances and intricacies of the area. Nevertheless, if the summaries database is extraordinarily dynamic and there’s worth in tracing again influences, contemplating a hybrid strategy or leaning in direction of RAG may very well be explored.
Query/answering system on organisational data (i.e. exterior knowledge)
1. Exterior data required? A query/answering system counting on organisational data bases inherently requires entry to exterior knowledge, on this case, the org’s inside databases and doc shops. The system’s effectiveness hinges on its potential to faucet into and retrieve related info from these sources to reply queries. Given this, RAG stands out because the extra appropriate alternative for this dimension, because it’s designed to reinforce LLM capabilities by retrieving pertinent knowledge from data sources.
2. Mannequin adaptation required? Relying on the group and its area, there is likely to be a requirement for the mannequin to align with particular terminologies, tones, or conventions. Whereas RAG focuses totally on info retrieval, finetuning might help the LLM modify its responses to the corporate’s inside vernacular or the nuances of its area. Thus, for this dimension, relying on the particular necessities finetuning may play a job.
3. Essential to minimise hallucinations? Hallucinations are a serious concern on this use case, because of the knowledge-cutoff of LLMs. If the mannequin is unable to reply a query primarily based on the information it has been skilled on, it can nearly actually revert to (partially or fully) making up a believable however incorrect reply.
4. Coaching knowledge accessible? If the group has a structured and labeled dataset of beforehand answered questions, this could bolster the finetuning strategy. Nevertheless, not all inside databases are labeled or structured for coaching functions. In situations the place the information isn’t neatly labeled or the place the first focus is on retrieving correct and related solutions, RAG’s potential to faucet into exterior knowledge sources without having an enormous labeled dataset makes it a compelling possibility.
5. How dynamic is the information? Inner databases and doc shops in organisations will be extremely dynamic, with frequent updates, modifications, or additions. If this dynamism is attribute of the organisation’s data base, RAG gives a definite benefit. It regularly queries the exterior sources, guaranteeing its solutions are primarily based on the newest accessible knowledge. Finetuning would require common retraining to maintain up with such modifications, which is likely to be impractical.
6. Transparency/Interpretability required? For inside purposes, particularly in sectors like finance, healthcare, or authorized, understanding the reasoning or supply behind a solution will be paramount. Since RAG supplies a two-step strategy of retrieval after which era, it inherently gives a clearer perception into which paperwork or knowledge factors influenced a selected reply. This traceability will be invaluable for inside stakeholders who may have to validate or additional examine the sources of sure solutions.
Advice: For this use case a RAG system appears to be the extra becoming alternative. Given the necessity for dynamic entry to the organisation’s evolving inside databases and the potential requirement for transparency within the answering course of, RAG gives capabilities that align nicely with these wants. Nevertheless, if there’s a major emphasis on tailoring the mannequin’s linguistic type or adapting to domain-specific nuances, incorporating parts of finetuning may very well be thought of.
Buyer Assist Automation (i.e. automated chatbots or assist desk options offering on the spot responses to buyer inquiries)
1. Exterior data required? Buyer assist usually necessitates entry to exterior knowledge, particularly when coping with product particulars, account-specific info, or troubleshooting databases. Whereas many queries will be addressed with common data, some may require pulling knowledge from firm databases or product FAQs. Right here, RAG’s functionality to retrieve pertinent info from exterior sources can be useful. Nevertheless, it’s price noting that a variety of buyer assist interactions are additionally primarily based on predefined scripts or data, which will be successfully addressed with a finetuned mannequin.
2. Mannequin adaptation required? Buyer interactions demand a sure tone, politeness, and readability, and may additionally require company-specific terminologies. Finetuning is particularly helpful for guaranteeing the LLM adapts to the corporate’s voice, branding, and particular terminologies, guaranteeing a constant and brand-aligned buyer expertise.
3. Essential to minimise hallucinations? For buyer assist chatbots, avoiding false info is important to keep up person belief. Finetuning alone leaves fashions liable to hallucinations when confronted with unfamiliar queries. In distinction, RAG methods suppress fabrications by grounding responses in retrieved proof. This reliance on sourced information permits RAG chatbots to minimise dangerous falsehoods and supply customers with dependable info the place accuracy is important.
4. Coaching knowledge accessible? If an organization has a historical past of buyer interactions, this knowledge will be invaluable for finetuning. A wealthy dataset of earlier buyer queries and their resolutions can be utilized to coach the mannequin to deal with comparable interactions sooner or later. If such knowledge is restricted, RAG can present a fallback by retrieving solutions from exterior sources like product documentation.
5. How dynamic is the information? Buyer assist may want to handle queries about new merchandise, up to date insurance policies, or altering service phrases. In situations the place the product line up, software program variations, or firm insurance policies are regularly up to date, RAG’s potential to dynamically pull from the newest paperwork or databases is advantageous. Then again, for extra static data domains, finetuning can suffice.
6. Transparency/Interpretability required? Whereas transparency is important in some sectors, in buyer assist, the first focus is on correct, quick, and courteous responses. Nevertheless, for inside monitoring, high quality assurance, or addressing buyer disputes, having traceability concerning the supply of a solution may very well be useful. In such instances, RAG’s retrieval mechanism gives an added layer of transparency.
Advice: For buyer assist automation a hybrid strategy is likely to be optimum. Finetuning can be certain that the chatbot aligns with the corporate’s branding, tone, and common data, dealing with the vast majority of typical buyer queries. RAG can then function a complementary system, stepping in for extra dynamic or particular inquiries, guaranteeing the chatbot can pull from the newest firm paperwork or databases and thereby minimising hallucinations. By integrating each approaches, firms can present a complete, well timed, and brand-consistent buyer assist expertise.
Picture by Creator
As talked about above, there are different elements that needs to be thought of when deciding between RAG and finetuning (or each). We are able to’t probably dive deep into them, as all of them are multi-faceted and don’t have clear solutions like among the elements above (for instance, if there isn’t a coaching knowledge the finetuning is simply merely not potential). However that doesn’t imply we should always disregard them:
Scalability
As an organisation grows and its wants evolve, how scalable are the strategies in query? RAG methods, given their modular nature, may supply extra easy scalability, particularly if the data base grows. Then again, regularly finetuning a mannequin to cater to increasing datasets will be computationally demanding.
Latency and Actual-time Necessities
If the appliance requires real-time or near-real-time responses, take into account the latency launched by every technique. RAG methods, which contain retrieving knowledge earlier than producing a response, may introduce extra latency in comparison with a finetuned LLM that generates responses primarily based on internalised data.
Upkeep and Assist
Take into consideration the long-term. Which system aligns higher with the organisation’s potential to supply constant upkeep and assist? RAG may require repairs of the database and the retrieval mechanism, whereas finetuning would necessitate constant retraining efforts, particularly if the information or necessities change.
Robustness and Reliability
How strong is every technique to several types of inputs? Whereas RAG methods can pull from exterior data sources and may deal with a broad array of questions, a nicely finetuned mannequin may supply extra consistency in sure domains.
Moral and Privateness Issues
Storing and retrieving from exterior databases may elevate privateness considerations, particularly if the information is delicate. Then again, a finetuned mannequin, whereas not querying reside databases, may nonetheless produce outputs primarily based on its coaching knowledge, which may have its personal moral implications.
Integration with Present Programs
Organisations may have already got sure infrastructure in place. The compatibility of RAG or finetuning with present methods — be it databases, cloud infrastructures, or person interfaces — can affect the selection.
Consumer Expertise
Take into account the end-users and their wants. In the event that they require detailed, reference-backed solutions, RAG may very well be preferable. In the event that they worth pace and domain-specific experience, a finetuned mannequin is likely to be extra appropriate.
Value
Finetuning can get costly, particularly for actually massive fashions. However previously few months prices have gone down considerably due to parameter environment friendly methods like QLoRA. Establishing RAG is usually a massive preliminary funding — overlaying the mixing, database entry, perhaps even licensing charges — however then there’s additionally the common upkeep of that exterior data base to consider.
Complexity
Finetuning can get complicated rapidly. Whereas many suppliers now supply one-click finetuning the place we simply want to supply the coaching knowledge, protecting observe of mannequin variations and guaranteeing that the brand new fashions nonetheless carry out nicely throughout the board is difficult. RAG, then again, also can get complicated rapidly. There’s the setup of a number of parts, ensuring the database stays contemporary, and guaranteeing the items — like retrieval and era — match collectively excellent.
As we’ve explored, selecting between RAG and finetuning requires a nuanced analysis of an LLM software’s distinctive wants and priorities. There isn’t a one-size-fits-all resolution; success lies in aligning the optimisation technique with the particular necessities of the duty. By assessing key standards — the necessity for exterior knowledge, adapting mannequin behaviour, coaching knowledge availability, knowledge dynamics, end result transparency, and extra — organisations could make an knowledgeable resolution on the perfect path ahead. In sure instances, a hybrid strategy leveraging each RAG and finetuning could also be optimum.
The secret’s avoiding assumptions that one technique is universally superior. Like every instrument, their suitability will depend on the job at hand. Misalignment of strategy and goals can hinder progress, whereas the precise technique accelerates it. As an organisation evaluates choices for reinforcing LLM purposes, it should resist oversimplification and never view RAG and finetuning as interchangeable and select the instrument that empowers the mannequin to fulfil its capabilities aligned to the wants of the use case. The chances these strategies unlock are astounding however chance alone isn’t sufficient — execution is all the things. The instruments are right here — now let’s put them to work.
Heiko Hotz is the Founding father of NLP London, an AI consultancy serving to organizations implement pure language processing and conversational AI. With over 15 years of expertise within the tech business, Heiko is an skilled in leveraging AI and machine studying to unravel complicated enterprise challenges.
Unique. Reposted with permission.
Heiko Hotz is the Founding father of NLP London, an AI consultancy serving to organizations implement pure language processing and conversational AI. With over 15 years of expertise within the tech business, Heiko is an skilled in leveraging AI and machine studying to unravel complicated enterprise challenges.