
{kind=link}

Picture by Creator
Deep Studying and Neural Networks encompass interconnected nodes, the place information is handed sequentially by every hidden layer. Nonetheless, the composition of linear capabilities is inevitably nonetheless a linear perform. Activation capabilities turn into vital when we have to study advanced and non-linear patterns inside our information.
The 2 main advantages of utilizing activation capabilities are:
Introduces Non-Linearity
Linear relationships are uncommon in real-world eventualities. Most real-world eventualities are advanced and comply with a wide range of completely different traits. Studying such patterns is unimaginable with linear algorithms like Linear and Logistic Regression. Activation capabilities add non-linearity to the mannequin, permitting it to study advanced patterns and variance within the information. This permits deep studying fashions to carry out sophisticated duties together with the picture and language domains.
Enable Deep Neural Layers
As talked about above, after we sequentially apply a number of linear capabilities, the output remains to be a linear mixture of the inputs. Introducing non-linear capabilities between every layer permits them to study completely different options of the enter information. With out activation capabilities, having a deeply related neural community structure would be the similar as utilizing fundamental Linear or Logistic Regression algorithms.
Activation capabilities enable deep studying architectures to study advanced patterns, making them extra highly effective than easy Machine Studying algorithms.
Let’s take a look at a few of the most typical activation capabilities utilized in deep studying.
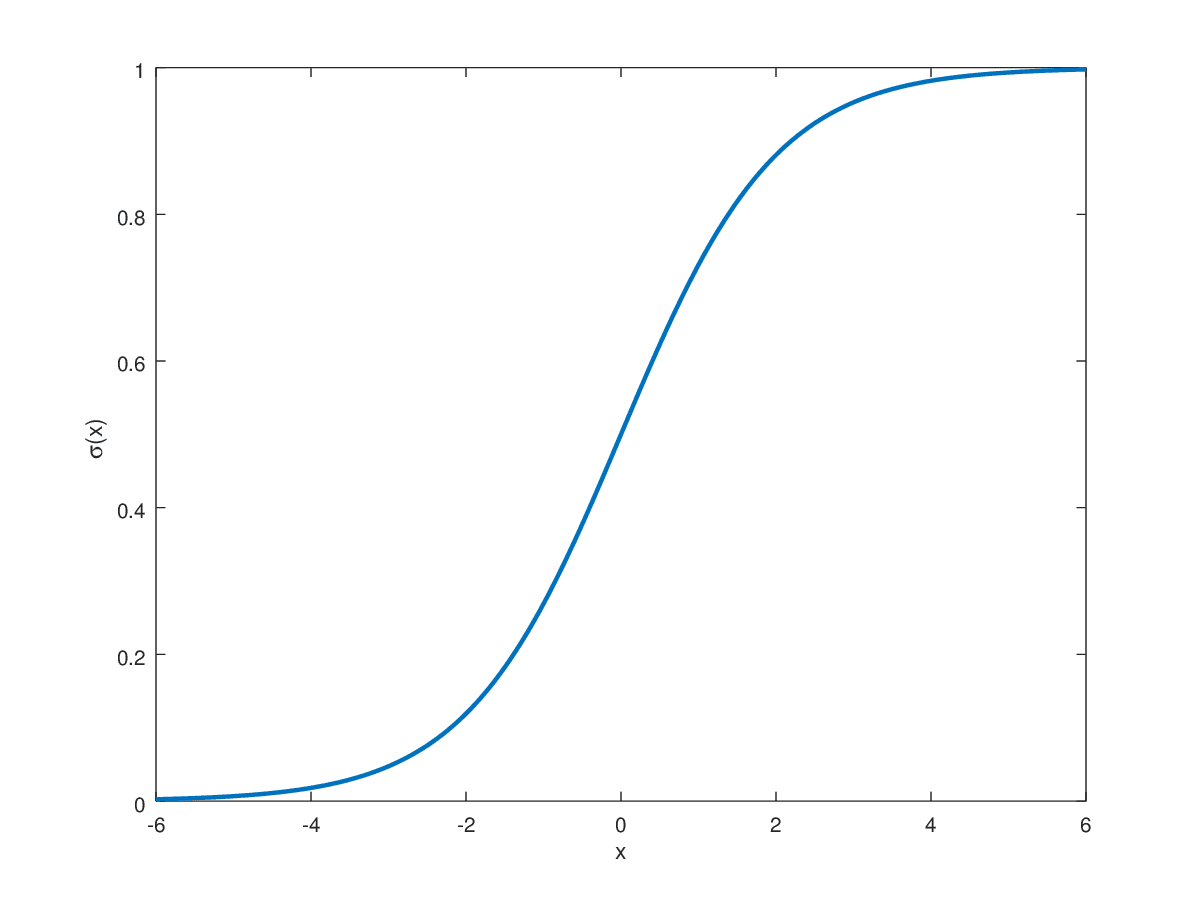
Generally utilized in binary classification duties, the Sigmoid perform maps real-numbered values between 0 and 1.
The above equation appears to be like as beneath:
Picture by Hvidberrrg
The Sigmoid perform is primarily used within the output layer for binary classification duties the place the goal label is both 0 or 1. This naturally makes Sigmoid preferable for such duties, because the output is restricted between this vary. For extremely constructive values that strategy infinity, the sigmoid perform maps them near 1. On the other finish, it maps values approaching unfavourable infinity to 0. All real-valued numbers between these are mapped within the vary 0 to 1 in an S-shaped development.
Shortcomings
Saturation Factors
The sigmoid perform poses issues for the gradient descent algorithm throughout backpropagation. Aside from values near the middle of the S-shaped curve, the gradient is extraordinarily near zero inflicting issues for coaching. Near the asymptotes, it will possibly result in vanishing gradient issues as small gradients can considerably decelerate convergence.
Not Zero-Centered
It is empirically confirmed that having a zero-centered non-linear perform ensures that the imply activation worth is near 0. Having such normalized values ensures sooner convergence of gradient descent in direction of the minima. Though not essential, having zero-centered activation permits sooner coaching. The Sigmoid perform is centered at 0.5 when the enter is 0. This is likely one of the drawbacks of utilizing Sigmoid in hidden layers.
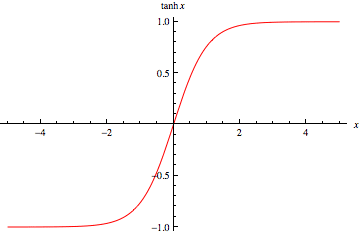
The hyperbolic tangent perform is an enchancment over the Sigmoid perform. As a substitute of the [0,1] vary, the TanH perform maps real-valued numbers between -1 and 1.
The Tanh perform appears to be like as beneath:
Picture by Wolfram
The TanH perform follows the identical S-shaped curve because the Sigmoid, however it’s now zero-centered. This enables sooner convergence throughout coaching because it improves on one of many shortcomings of the Sigmoid perform. This makes it extra appropriate to be used in hidden layers in a neural community structure.
Shortcomings
Saturation Factors
The TanH perform follows the identical S-shaped curve because the Sigmoid, however it’s now zero-centered. This enables sooner convergence throughout coaching bettering upon the Sigmoid perform. This makes it extra appropriate to be used in hidden layers in a neural community structure.
Computational Expense
Though not a significant concern within the modern-day, the exponential calculation is costlier than different widespread alternate options out there.
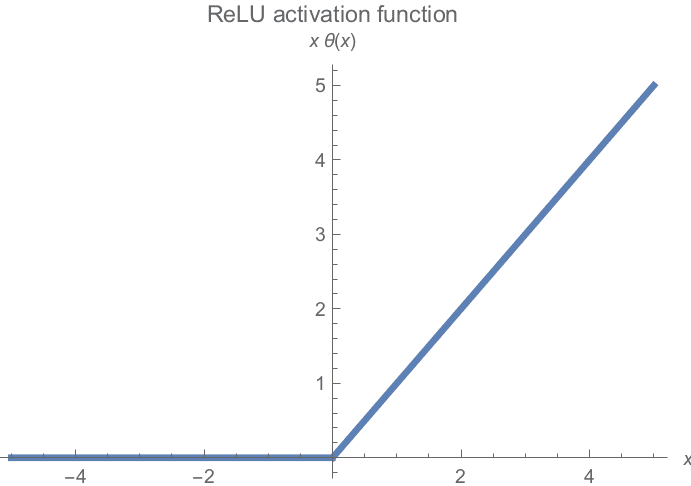
Probably the most generally used activation perform in follow, Rectified Linear Unit Activation (ReLU) is the simplest but handiest attainable non-linear perform.
It conserves all non-negative values and clamps all unfavourable values to 0. Visualized, the ReLU capabilities look as follows:
Picture by Michiel Straat
Shortcomings
Dying ReLU
The gradient flattens at one finish of the graph. All unfavourable values have zero gradients, so half of the neurons might have minimal contribution to coaching.
Unbounded Activation
On the right-hand aspect of the graph, there is no such thing as a restrict on the attainable gradient. This will result in an exploding gradient downside if the gradient values are too excessive. This situation is generally corrected by Gradient Clipping and Weight Initialization methods.
Not Zero-Centered
Much like Sigmoid, the ReLU activation perform can be not zero-centered. Likewise, this causes issues with convergence and may decelerate coaching.
Regardless of all shortcomings, it’s the default selection for all hidden layers in neural community architectures and is empirically confirmed to be extremely environment friendly in follow.
Now that we all know concerning the three most typical activation capabilities, how do we all know what’s the absolute best selection for our state of affairs?
Though it extremely will depend on the info distribution and particular downside assertion, there are nonetheless some fundamental beginning factors which are broadly utilized in follow.
- Sigmoid is simply appropriate for output activations of binary issues when goal labels are both 0 or 1.
- Tanh is now majorly changed by the ReLU and comparable capabilities. Nonetheless, it’s nonetheless utilized in hidden layers for RNNs.
- In all different eventualities, ReLU is the default selection for hidden layers in deep studying architectures.
Muhammad Arham is a Deep Studying Engineer working in Laptop Imaginative and prescient and Pure Language Processing. He has labored on the deployment and optimizations of a number of generative AI functions that reached the worldwide high charts at Vyro.AI. He’s inquisitive about constructing and optimizing machine studying fashions for clever techniques and believes in continuous enchancment.