

{kind=link}
Have you ever ever puzzled how surveillance programs work and the way we will determine people or automobiles utilizing simply movies? Or how is an orca recognized utilizing underwater documentaries? Or maybe stay sports activities evaluation? All that is finished through video segmentation. Video segmentation is the method of partitioning movies into a number of areas based mostly on sure traits, akin to object boundaries, movement, coloration, texture, or different visible options. The fundamental thought is to determine and separate completely different objects from the background and temporal occasions in a video and to offer a extra detailed and structured illustration of the visible content material.
Increasing the usage of algorithms for video segmentation will be expensive as a result of it requires labeling quite a lot of information. To make it simpler to trace objects in movies while not having to coach the algorithm for every particular job, researchers have give you a decoupled video segmentation DEVA. DEVA entails two most important elements: one which’s specialised for every job to seek out objects in particular person frames and one other half that helps join the dots over time, no matter what the objects are. This fashion, DEVA will be extra versatile and adaptable for numerous video segmentation duties with out the necessity for in depth coaching information.
With this design, we will get away with having an easier image-level mannequin for the precise job we’re inquisitive about (which is inexpensive to coach) and a common temporal propagation mannequin that solely must be educated as soon as and might work for numerous duties. To make these two modules work collectively successfully, researchers use a bi-directional propagation method. This helps to merge segmentation guesses from completely different frames in a means that makes the ultimate segmentation look constant, even when it’s finished on-line or in actual time.
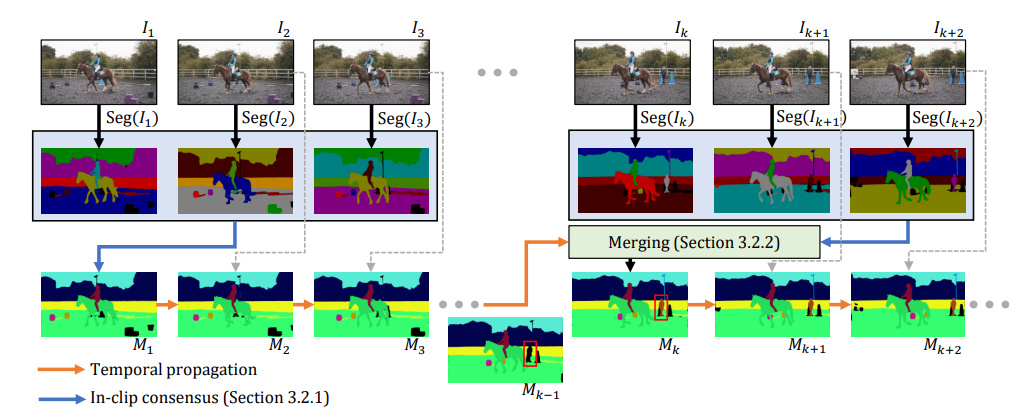
The above picture gives us with an summary of the framework. The analysis crew first filters image-level segmentations with in-clip consensus and temporally propagates this outcome ahead. To include a brand new picture segmentation at a later time step (for beforehand unseen objects, e.g., crimson field), they merge the propagated outcomes with in-clip consensus.
The method adopted on this analysis makes vital use of exterior task-agnostic information, aiming to lower dependence on the precise goal job. It ends in higher generalization capabilities, notably for duties with restricted obtainable information in comparison with end-to-end strategies. It doesn’t even require fine-tuning. When paired with common picture segmentation fashions, this decoupled paradigm showcases cutting-edge efficiency. It most positively represents an preliminary stride in direction of reaching state-of-the-art large-vocabulary video segmentation in an open-world context!
Take a look at the Paper, Github, and Challenge Web page. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t neglect to affix our 30k+ ML SubReddit, 40k+ Fb Neighborhood, Discord Channel, and Electronic mail Publication, the place we share the newest AI analysis information, cool AI initiatives, and extra.
In the event you like our work, you’ll love our publication..
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming information scientist and has been working on the planet of ml/ai analysis for the previous two years. She is most fascinated by this ever altering world and its fixed demand of people to maintain up with it. In her pastime she enjoys touring, studying and writing poems.