


{kind=link}
Most of us take care of PDF recordsdata often. There are all the time situations when you have to extract particular pages from giant PDFs — an expense declare from a bulk obtain, a web page from an instructional paper, a desk from a prolonged report, or perhaps a recipe from a big cookbook.
So, how do you extract a web page or a number of pages from a PDF? No one needs to resort to copying-and-pasting or printing and scanning. These strategies are tedious, time-consuming, and may end up in lack of high quality.
This text will record 5 totally different strategies to extract pages from a PDF doc. We’ll information you thru every approach step-by-step so you may select the one which’s best for you and even mix them for optimum effectivity.
PDF is extensively used as a result of it’s transportable, provides safety, and preserves formatting. Nonetheless, a big PDF might be cumbersome, particularly whenever you solely want sure pages. The necessity to extract pages from a PDF may come up for a number of causes:
- Sharing particular elements of a doc
- Eradicating confidential info
- Sending solely related info to preserve house and time
- Creating a brand new doc from elements of an present one
- Extracting solely the abstract or temporary of a complete report
Irrespective of your purpose, extracting pages from a PDF could make your work considerably extra simple. Now, let’s dive into the totally different strategies to extract pages from a PDF.
That is probably the most simple technique to extract a web page from a PDF. You don’t have to obtain or set up any software program. Most PDF readers have a print perform that means that you can choose the pages you need and print them to a brand new PDF file.
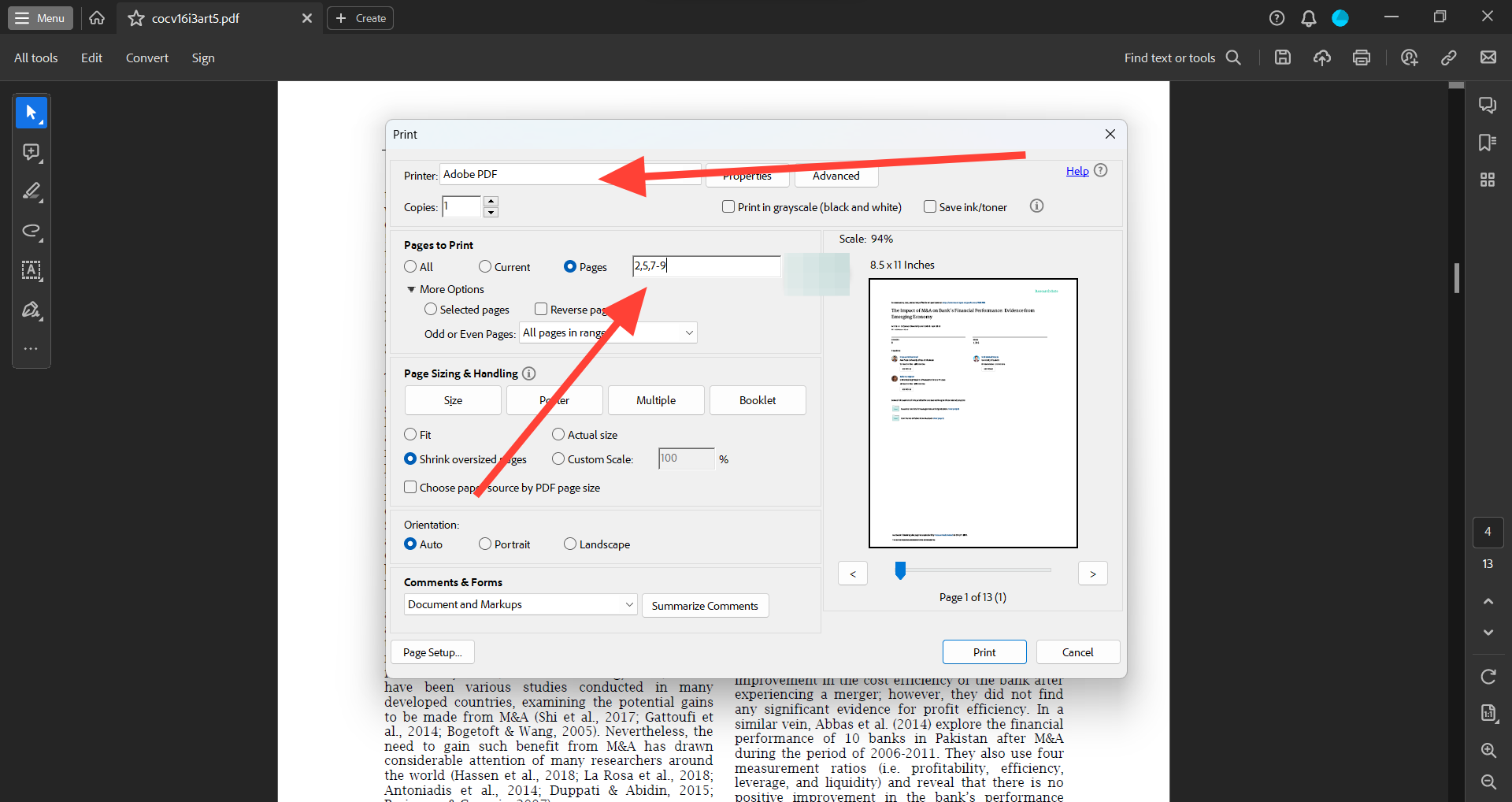
Let’s have a look at methods to extract a web page from a PDF utilizing Adobe Reader:
- Open the PDF file from which you want to extract pages
- Click on on ‘Menu’
- Select the ‘Print’ choice
- Specify the pages you need to extract within the area subsequent to ‘Pages to Print’
- Set the ‘Printer’ as ‘Adobe PDF’
- Click on ‘Print’
- Select the situation the place you need to save the extracted pages and rename the brand new PDF file
- Click on ‘Save’
This may create a brand new PDF file containing the pages you specified. You may enter particular person pages, web page ranges, and a mix of each (ought to be separated by commas).
Whereas this technique is easy and does not require particular instruments, it has a number of drawbacks. Misaligned web page numbers may result in incorrect pages being extracted. Bulk processing could also be sophisticated since you should manually enter every web page quantity.
There is no choice to rearrange the pages post-extraction. And the output stays a PDF — you can’t select a distinct output format.
Notice: This technique won’t work if the PDF is password-protected or printing is disabled.
Now, when you’d prefer to extract pages from a PDF on a extra skilled scale, you may need to attempt Adobe’s Acrobat. This software program just isn’t free however provides a 7-day free trial.
The Acrobat Professional plan begins at $19.99/month, and it comes with a collection of options that may assist optimize your document-handling course of.
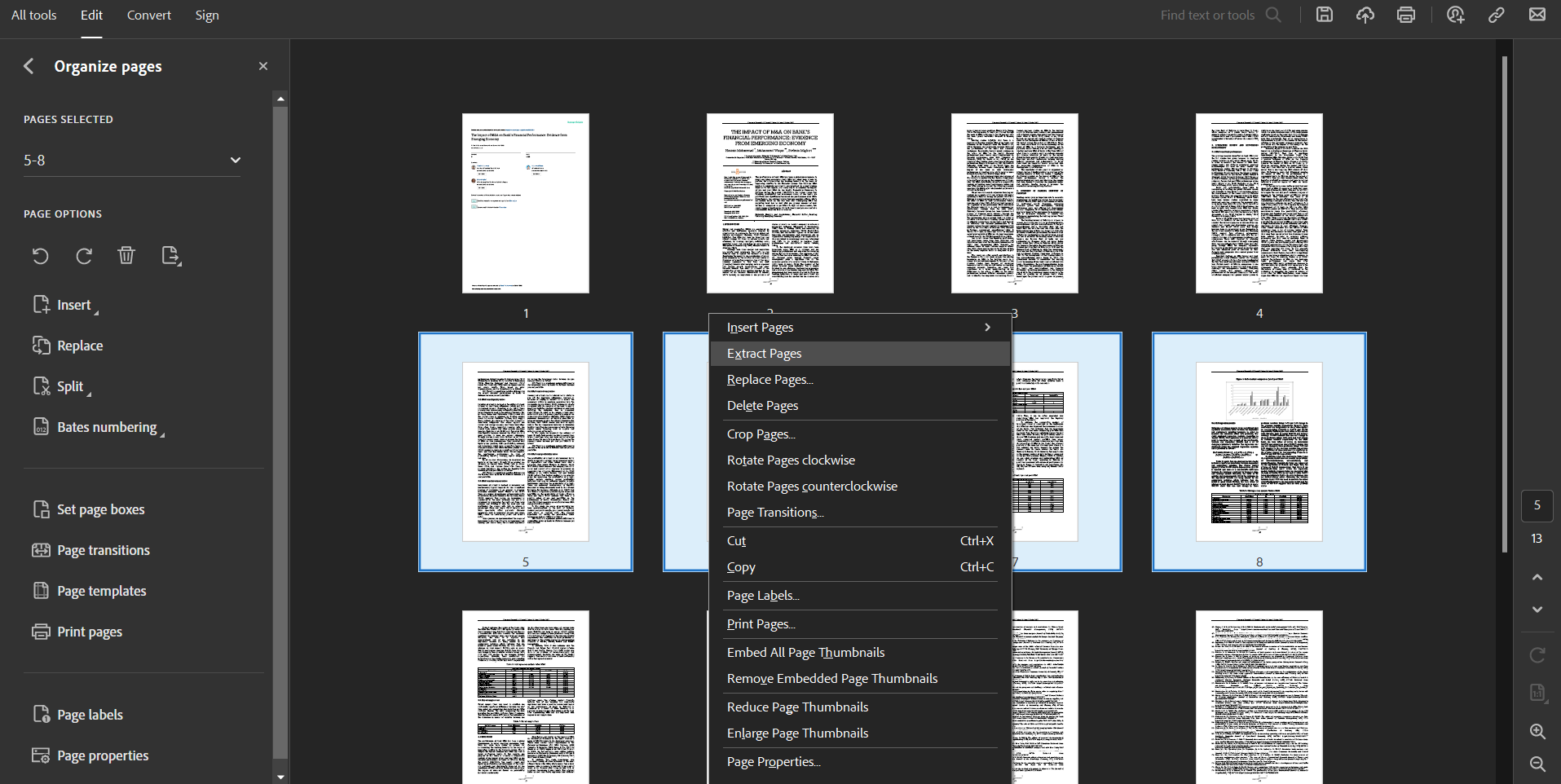
Right here is how one can extract pages utilizing Adobe Acrobat:
- Open the PDF file you need to extract pages from in Adobe Acrobat
- Click on on the ‘Edit’ menu
- Select ‘Manage Pages’
- Press Management (on Home windows) or Command (on Mac) and click on on the pages you need to extract
- Proper-click on the chosen pages
- Select ‘Extract Pages’
- Within the new dialog field, verify ‘Extract Pages As Separate Recordsdata’ if you would like every web page as a separate PDF
- Select the situation the place you need to save the extracted pages
- Click on ‘Extract’
This technique works effectively as a result of it retains all interactive elements of the PDF, comparable to hyperlinks, feedback, and varieties. It additionally means that you can extract as many pages as you need and save them as separate recordsdata and even cut up the PDF into a number of PDFs.
Nonetheless, it’s a must to purchase the software program after the trial interval, and it may be fairly costly when you solely want it for easy duties. It additionally doesn’t present an choice to convert the extracted pages into different file codecs other than PDF.
3. Utilizing PDFs to on-line PDF splitters
PDF splitters can turn out to be useful when you don’t need to obtain a reader or pay for Adobe Acrobat. There are quite a few free on-line instruments that permit you to cut up PDF recordsdata and extract particular pages.
All it’s a must to do is add your PDF to the web site, specify the pages you need to extract and obtain the brand new PDF.
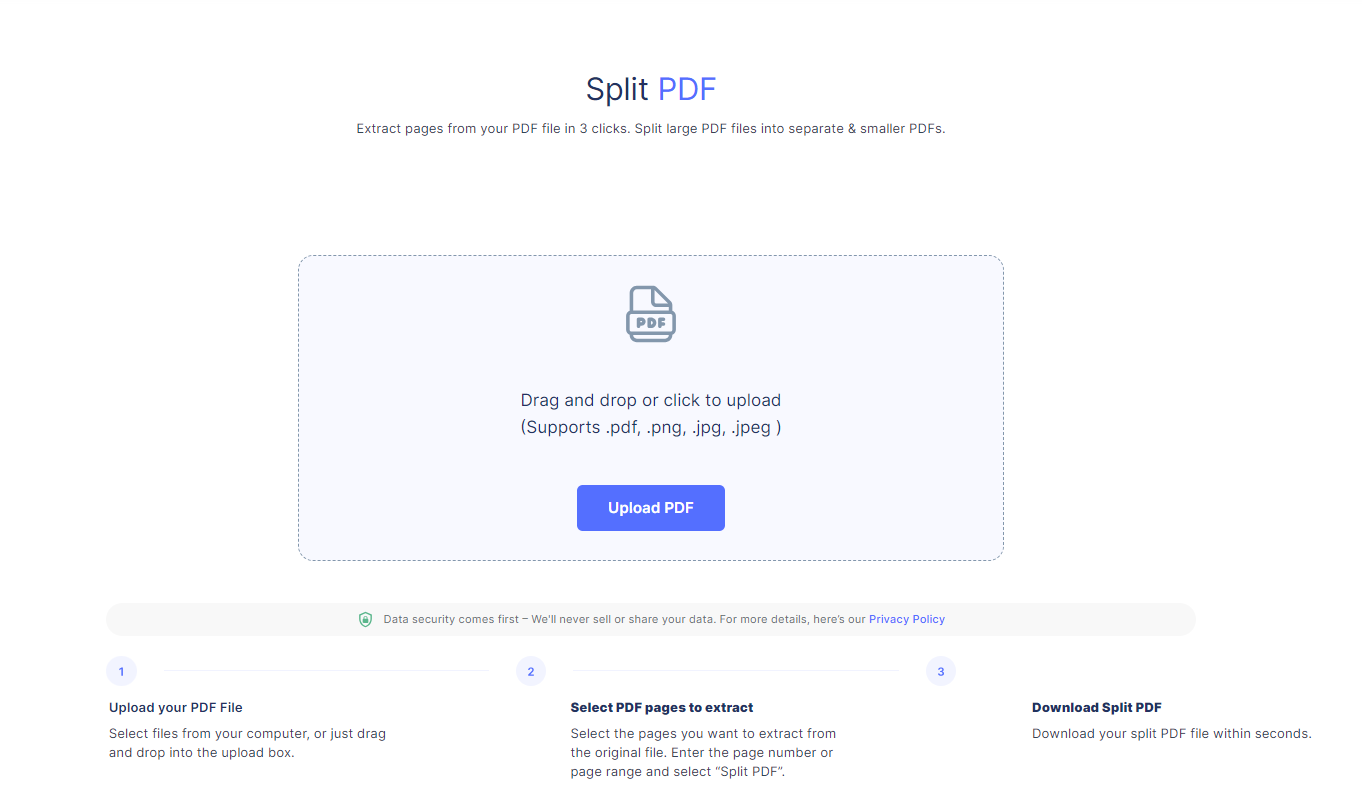
Among the common on-line PDF splitter instruments embrace:
This is a normal information on methods to use these on-line PDF splitters to extract a web page from a PDF:
- Go to the web site of the web software you’ve gotten chosen
- Click on on ‘Choose PDF file’ or an identical choice to add your PDF
- As soon as the PDF is uploaded, choose the pages you need to extract
- Click on ‘Extract pages’ or an identical choice
- Obtain the brand new PDF file with the extracted pages
These on-line instruments are easy to make use of, and most are free. Many of those instruments include extra options, comparable to merging PDFs, changing between totally different file codecs, compressing PDFs, and extra. However be ready to discover a bit, as every element often has its web page or tab.
One main draw back of on-line instruments is the chance of importing confidential or delicate paperwork to a third-party server. Your file may find yourself within the incorrect arms if the web site’s safety is compromised. So, when you’re dealing with confidential knowledge, rapidly verify the web site’s privateness coverage.
Velocity might be one other hiccup. Server or community congestion can sluggish issues down, particularly with giant recordsdata. Additionally, the free model might restrict some options, throw adverts at you, or nudge you to improve for speedier processing. Take SmallPDF, for instance; you may’t rename your extracted file with out paying up.
The standard of your output may also be hit and miss relying on the software, and there could be a cap on what number of pages you may extract in a single go.
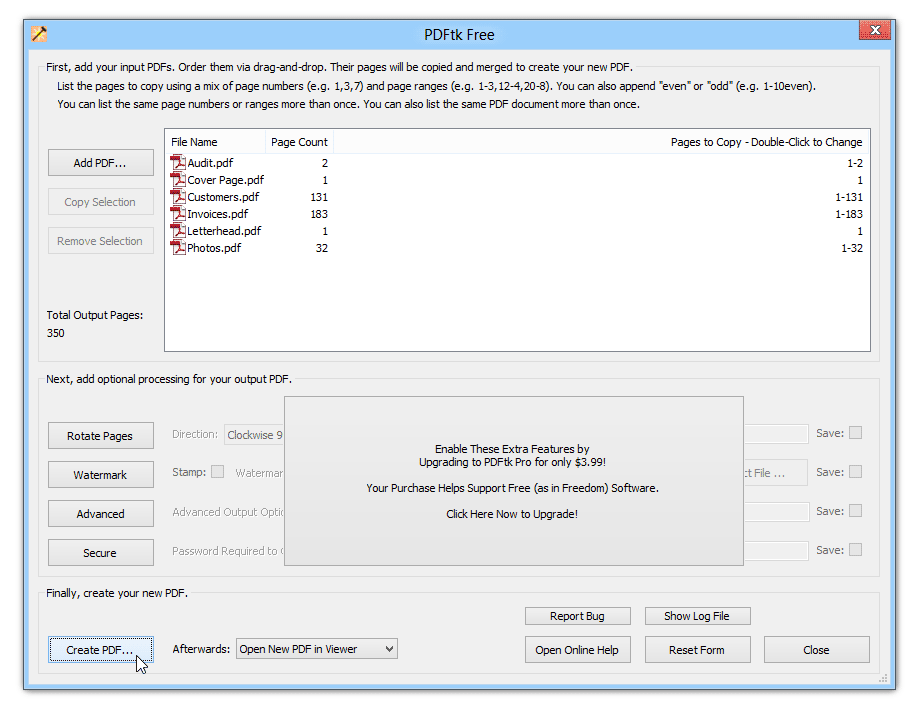
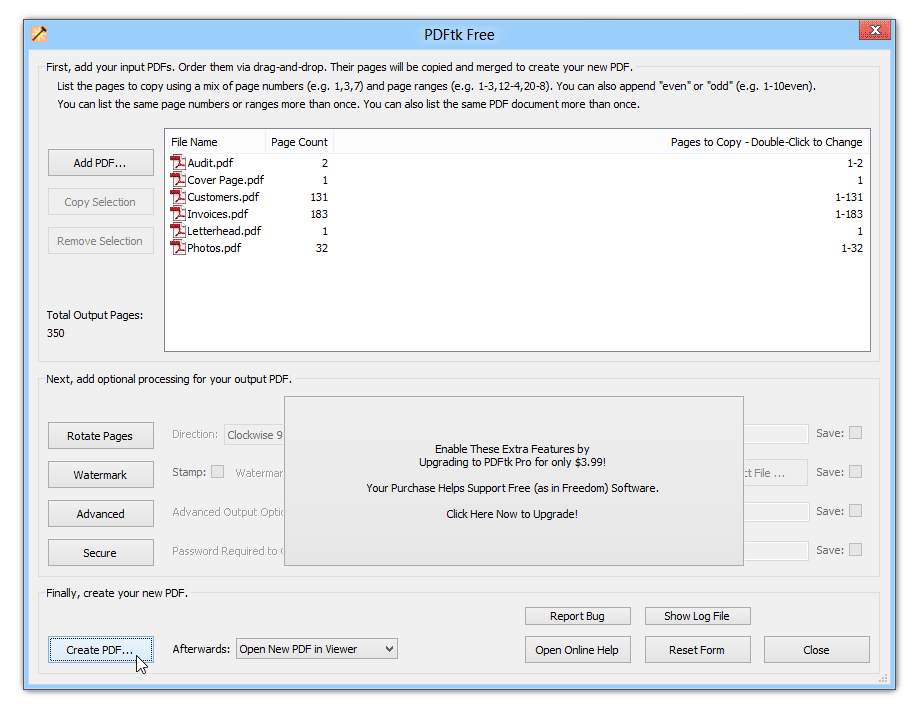
Processing confidential paperwork or coping with bulk recordsdata? Open-source software program could be the answer for you.
{kind=link}
These instruments are free, and you need to use them in your native machine, avoiding the safety issues related to on-line instruments. They are typically far more highly effective and versatile, providing many choices for dealing with PDF recordsdata.
Some open-source PDF extraction instruments embrace:
- PDFsam Visible
- OCRmyPDF
- PDFMate
- PDFtk
- PDFill
This is a normal information to extracting pages utilizing open-source software program:
- Obtain and set up the open-source software program of your alternative
- Open the software program and cargo your PDF file
- Select the ‘Extract’ or ‘Cut up’ perform (the precise wording will depend upon the software program)
- Specify the pages you need to extract
- Click on ‘Extract’ or ‘Cut up’
- Select the situation the place you need to save the extracted pages
- Click on ‘Save’ or ‘OK’
With these instruments, you may extract, merge, rotate, and carry out many different operations in your PDF recordsdata. In addition they often help batch processing as a way to extract pages from a number of PDFs directly.
One potential disadvantage of open-source software program is that they may not be as user-friendly as on-line instruments or industrial software program. You may have to learn the documentation, take care of command-line interfaces, and deal with occasional bugs. You may want some technical data to get probably the most out of them.
Additionally, whereas these instruments can deal with most PDF duties, they could not help superior options like interactive components, annotations, or encryption. Some may lack a graphical consumer interface, making them tougher for non-technical customers to navigate.
Many of the abovementioned instruments work nice when info extraction relies on web page numbers. However what if you have to extract pages based mostly on the web page’s content material?
As an example, you need to extract and course of all of the invoices with a price of over $500 or all of the pages with a selected identify or time period. An AI-powered OCR (Optical Character Recognition) software might be useful in such instances.

Nanonets enables you to automate the method of extracting knowledge from PDFs. With its AI capabilities, Nanonets can acknowledge and extract particular content material out of your pages, making info extraction extra environment friendly and exact.
This is a normal information to automate the extraction of knowledge from PDFs utilizing Nanonets:
- Join a free account on Nanonets
- Add your PDF recordsdata
- Configure the AI mannequin by deciding on the information fields you need to extract
- Practice the mannequin by offering some examples
- As soon as the mannequin is skilled, extract your required knowledge from the uploaded PDF
- Obtain the extracted knowledge in your most well-liked format (CSV, JSON, and so on.)
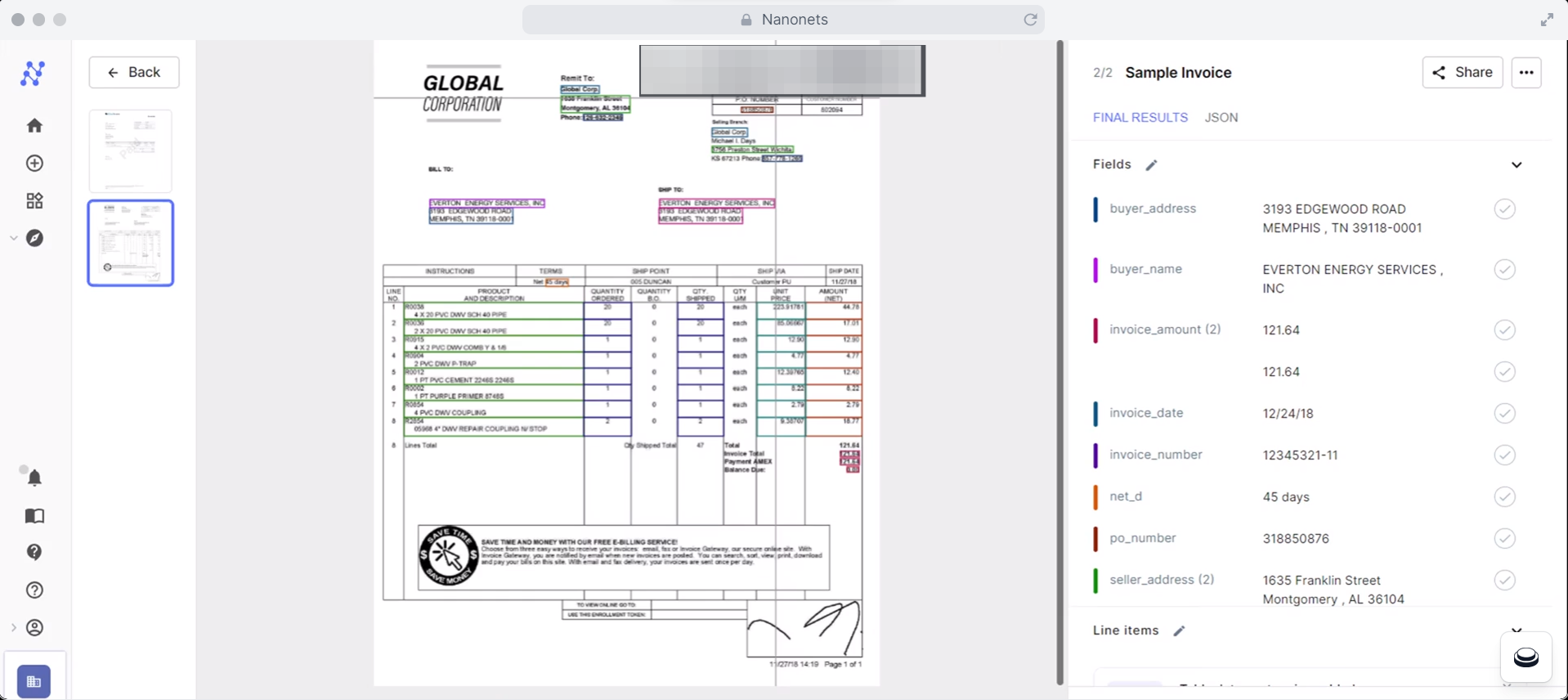
Add any variety of PDFs and let Nanonets do the heavy lifting for you. The software can course of a number of recordsdata concurrently, saving you appreciable effort and time.
Nanonets combines superior OCR and AI know-how to acknowledge textual content, numbers, and different knowledge in your receipts, invoices, financial institution statements, buy orders, and different paperwork. It could make your PDFs searchable and course of advanced paperwork with a number of layouts, languages, and buildings.

This permits the software to deal with structured and unstructured paperwork and precisely extract solely the data you want. Furthermore, it learns out of your intervention and improves over time.
What’s extra, Nanonets comes with pre-built, low-code automation workflows. You may automate the complete course of from extraction, verification, and validation to creating audit trails, processing funds, or every other operation. This lets you course of paperwork quicker, scale back handbook errors, and save beneficial time.
Nanonets integrates seamlessly together with your present techniques like ERP, CRM, and accounting software program. Be it Xero, QuickBooks, Salesforce, or every other utility, you may immediately feed the extracted knowledge into these techniques with minimal handbook intervention.
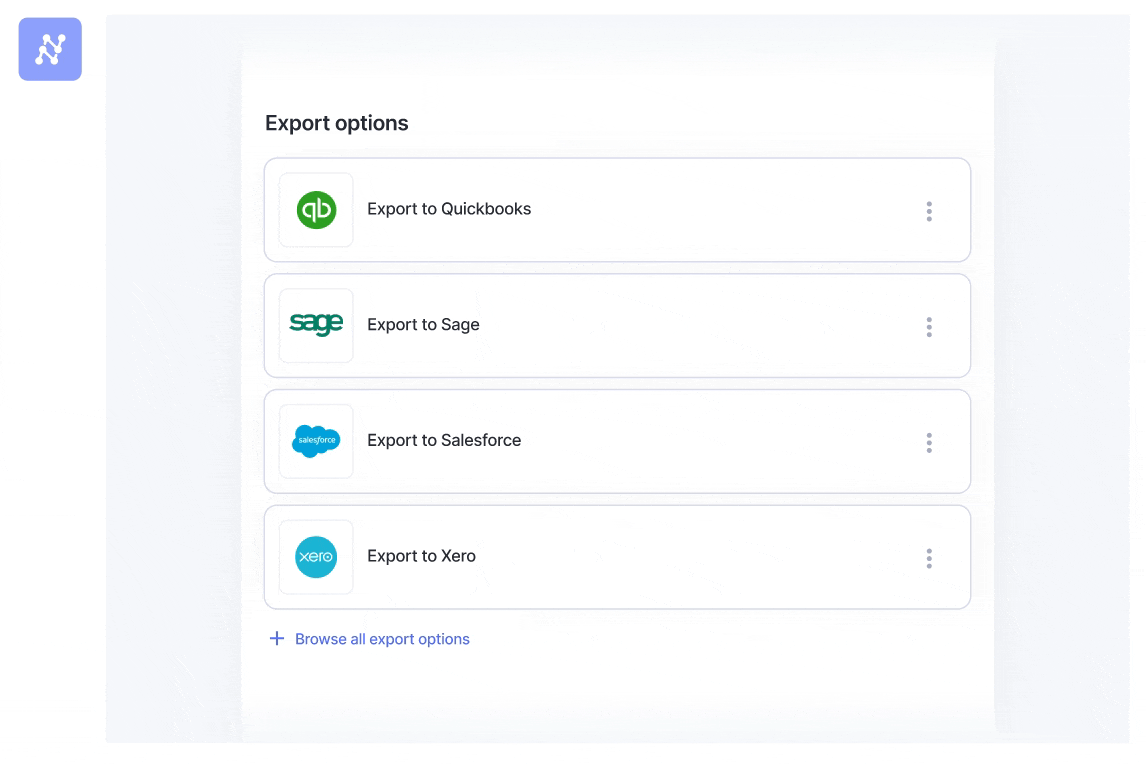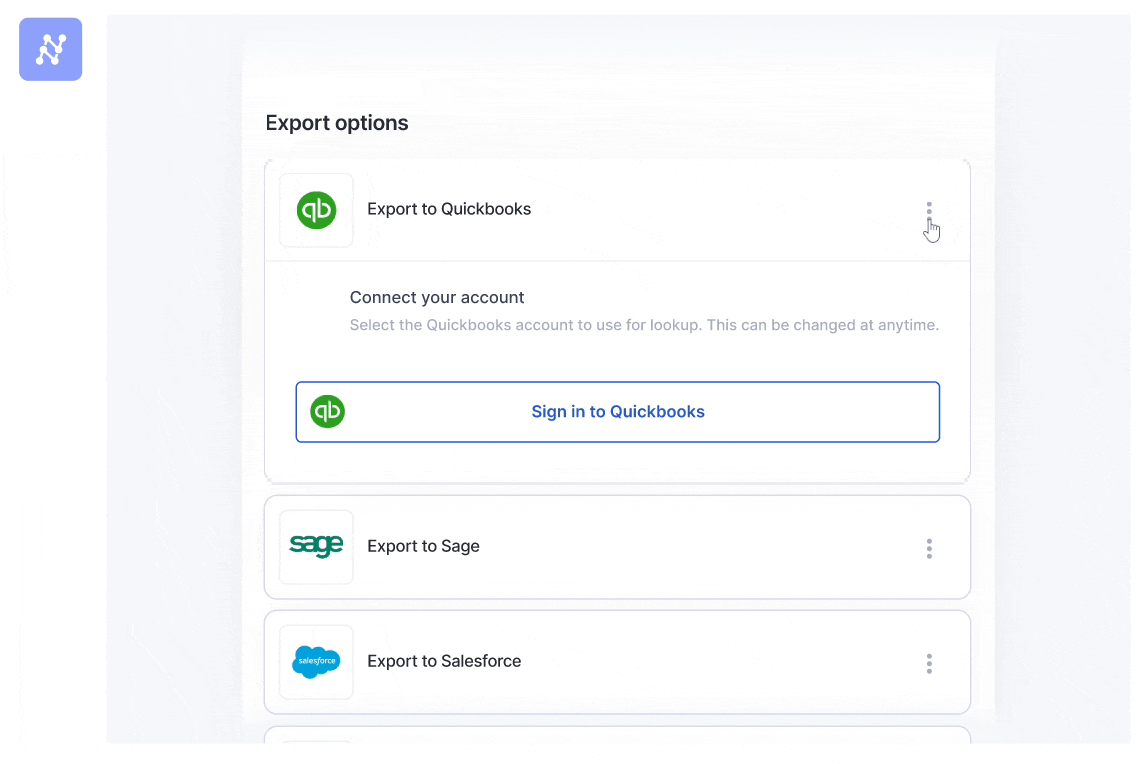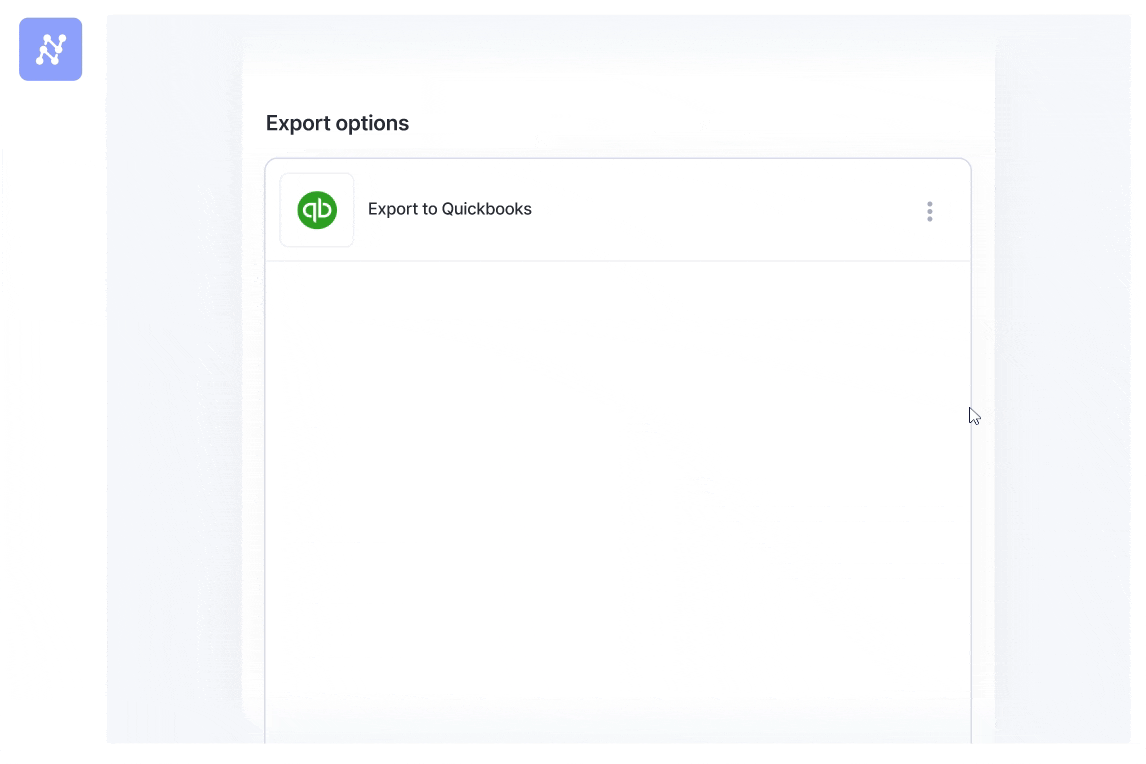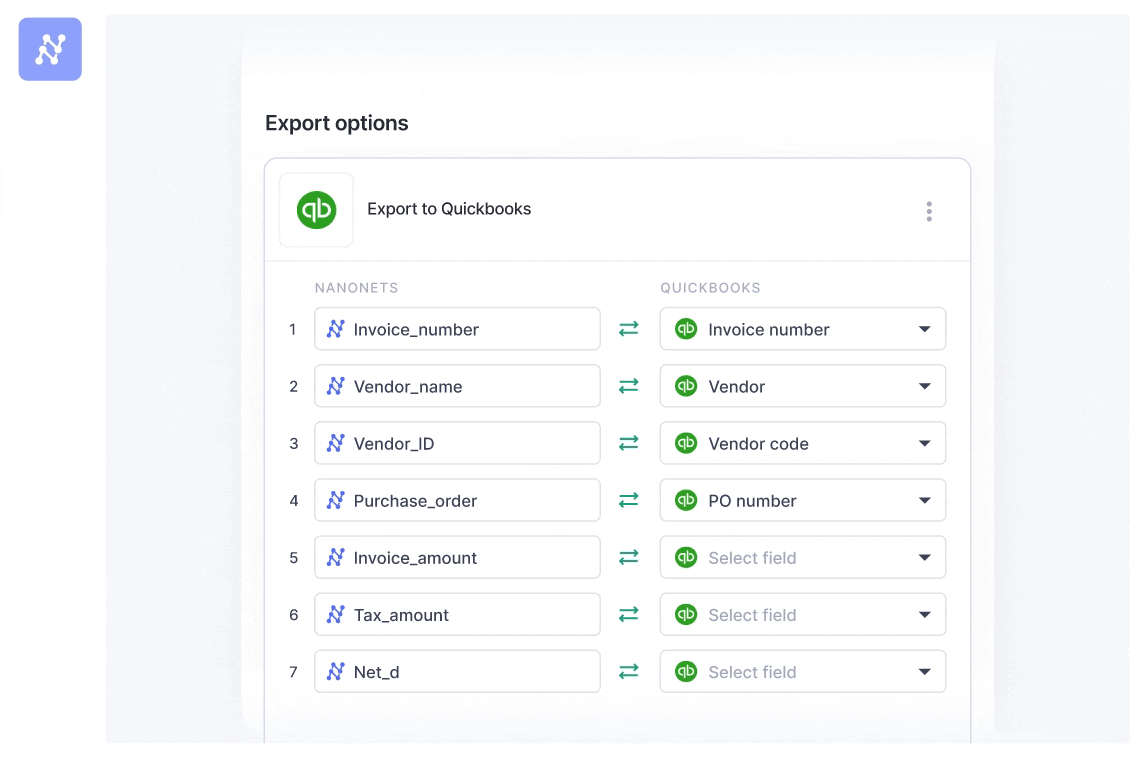
It additionally helps doc storage companies like Google Drive, Dropbox, and SharePoint, permitting you to entry and handle your paperwork simply.
For these involved about knowledge safety, Nanonets makes use of encryption for knowledge safety and ensures that your knowledge is processed in a safe atmosphere. It additionally respects knowledge privateness laws like GDPR and CCPA.
Wrapping up
There you’ve gotten it — 5 other ways to extract pages from a PDF. Hopefully, this information has given you a clearer concept of methods to strategy your PDF extraction duties.
At all times consider the complexity of your paperwork, the effort and time you may afford to spend, and the extent of accuracy required earlier than selecting a way. The suitable software generally is a actual game-changer. It could prevent hours of handbook work, forestall errors, streamline your workflow, and enable you give attention to extra crucial duties.